[ad_1]
![]() Amazon Redshift is a data warehouse that can expand to exabyte-scale. Today, tens of thousands of AWS customers (including NTT DOCOMO, Finra, and Johnson & Johnson) use Redshift to run mission-critical BI dashboards, analyze real-time streaming data, and run predictive analytics jobs.
Amazon Redshift is a data warehouse that can expand to exabyte-scale. Today, tens of thousands of AWS customers (including NTT DOCOMO, Finra, and Johnson & Johnson) use Redshift to run mission-critical BI dashboards, analyze real-time streaming data, and run predictive analytics jobs.
A challenge arises when the number of concurrent queries grows at peak times. When a multitude of business analysts all turn to their BI dashboards or long-running data science workloads compete with other workloads for resources, Redshift will queue queries until enough compute resources become available in the cluster. This ensures that all of the work gets done, but it can mean that performance is impacted at peak times. Two options present themselves:
- Overprovision the cluster to meet peak needs. This option addresses the immediate issue, but wastes resources and costs more than necessary.
- Optimize the cluster for typical workloads. This option forces you to wait longer for results at peak times, possibly delaying important business decisions.
New Concurrency Scaling
Today I would like to offer a third option. You can now configure Redshift to add more query processing power on an as-needed basis. This happens transparently and in a manner of seconds, and provides you with fast, consistent performance even as the workload grows to hundreds of concurrent queries. Additional processing power is ready in seconds and does not need to be pre-warmed or pre-provisioned. You pay only for what you use, with per-second billing and also accumulate one hour of concurrency scaling cluster credits every 24 hours while your main cluster is running. The extra processing power is removed when it is no longer needed, making this a perfect way to address the bursty use cases that I described above.
You can allocate the burst power to specific users or queues, and you can continue to use your existing BI and ETL applications. Concurrency Scaling Clusters are used to handle many forms of read-only queries, with additional flexibility in the works; read about Concurrency Scaling to learn more.
Using Concurrency Scaling
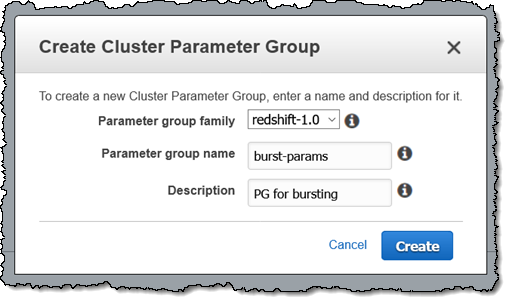
This feature can be enabled for an existing cluster in minutes! We recommend starting with a fresh Redshift Parameter Group for testing purposes, so I start by creating one:
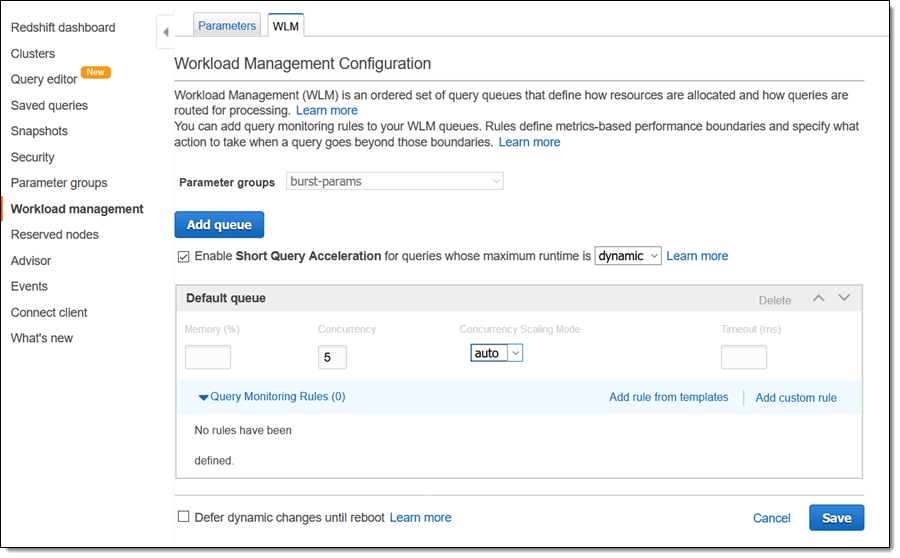
Then I edit my cluster’s Workload Management Configuration, select the new parameter group, set the Concurrency Scaling Mode to auto, and click Save:
 I will use the Cloud Data Warehouse Benchmark Derived From TPC-DS as a source of test data and test queries. I download the DDL, customize it with my AWS credentials, and use psql to connect to my cluster and create the test data:
I will use the Cloud Data Warehouse Benchmark Derived From TPC-DS as a source of test data and test queries. I download the DDL, customize it with my AWS credentials, and use psql to connect to my cluster and create the test data:
The DDL creates the tables and loads populates them using data stored in an S3 bucket:
Then I download the queries and open up a bunch of PuTTY windows so that I can generate a meaningful load for my Redshift cluster:
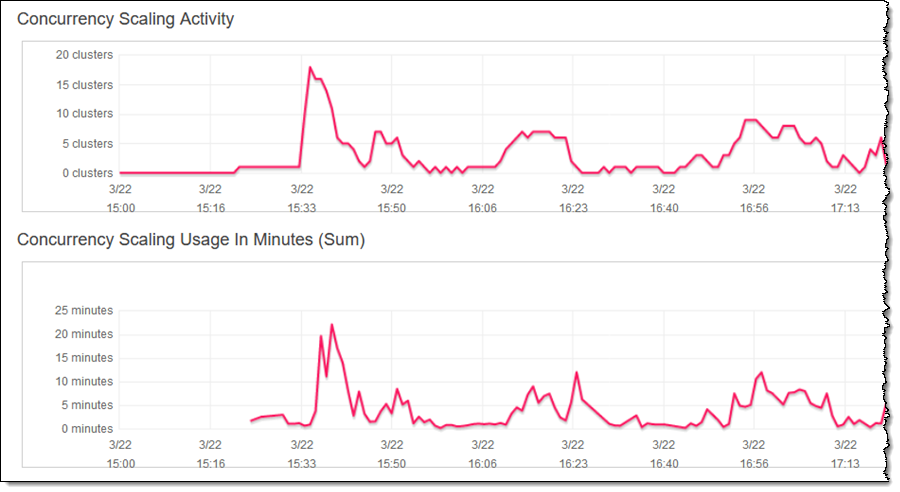
I run an initial set of parallel queries, and then ramp up over time, I can see them in the Cluster Performance tab for my cluster:
I can see the additional processing power come online as needed, and then go away when no longer needed, in the Database Performance tab:
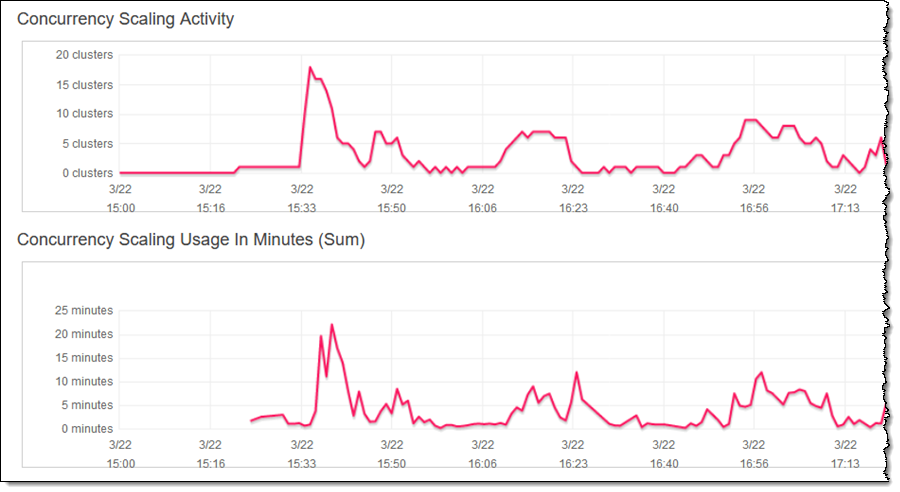
As you can see, my cluster scales as needed in order to handle all of the queries as expeditiously as possible. The Concurrency Scaling Usage shows me how many seconds of additional processing power I have consumed (as I noted earlier, each cluster accumulates a full hour of concurrency credits every 24 hours).
I can use the parameter max_concurrency_scaling_clusters to control the number of Concurrency Scaling Clusters that can be used (the default limit is 10, but you can request an increase if you need more).
Available Today
You can start making use of Concurrency Scaling Clusters today in the US East (N. Virginia), US East (Ohio), US West (Oregon), Europe (Ireland), and Asia Pacific (Tokyo) Regions today, with more to come later this year.
— Jeff;
[ad_2]
Source link
Recent Comments