
[ad_1]
 AWS gives you the power to easily and dynamically create file systems, block storage volumes, relational databases, NoSQL databases, and other resources that store precious data. You can create them on a moment’s notice as the need arises, giving you access to as much storage as you need and opening the door to large-scale cloud migration. When you bring your sensitive data to the cloud, you need to make sure that you continue to meet business and regulatory compliance requirements, and you definitely want to make sure that you are protected against application errors.
AWS gives you the power to easily and dynamically create file systems, block storage volumes, relational databases, NoSQL databases, and other resources that store precious data. You can create them on a moment’s notice as the need arises, giving you access to as much storage as you need and opening the door to large-scale cloud migration. When you bring your sensitive data to the cloud, you need to make sure that you continue to meet business and regulatory compliance requirements, and you definitely want to make sure that you are protected against application errors.
While you can build your own backup tools using the built-in snapshot operations built in to many of the services that I listed above, creating an enterprise wide backup strategy and the tools to implement it still takes a lot of work. We are changing that.
New AWS Backup
AWS Backup is designed to help you automate and centrally manage your backups. You can create policy-driven backup plans, monitor the status of on-going backups, verify compliance, and find / restore backups, all using a central console. Using a combination of the existing AWS snapshot operations and new, purpose-built backup operations, Backup backs up EBS volumes, EFS file systems, RDS databases, DynamoDB tables, and Storage Gateway volumes to Amazon Simple Storage Service (S3), with the ability to tier older backups to Amazon Glacier. Because Backup includes support for Storage Gateway volumes, you can include your existing, on-premises data in the backups that you create.
Each backup plan includes one or more backup rules. The rules express the backup schedule, frequency, and backup window. Resources to be backed-up can be identified explicitly or in a policy-driven fashion using tags. Lifecycle rules control storage tiering and expiration of older backups. Backup gathers the set of snapshots and the metadata that goes along with the snapshots into collections that define a recovery point. You get lots of control so that you can define your daily / weekly / monthly backup strategy, the ability to rest assured that your critical data is being backed up in accord with your requirements, and the ability to restore that data on an as-needed data. Backups are grouped into vaults, each encrypted by a KMS key.
Using AWS Backup
You can get started with AWS Backup in minutes. Open the AWS Backup Console and click Create backup plan:

I can build a plan from scratch, start from an existing plan or define one using JSON. I’ll Build a new plan, and start by giving my plan a name:
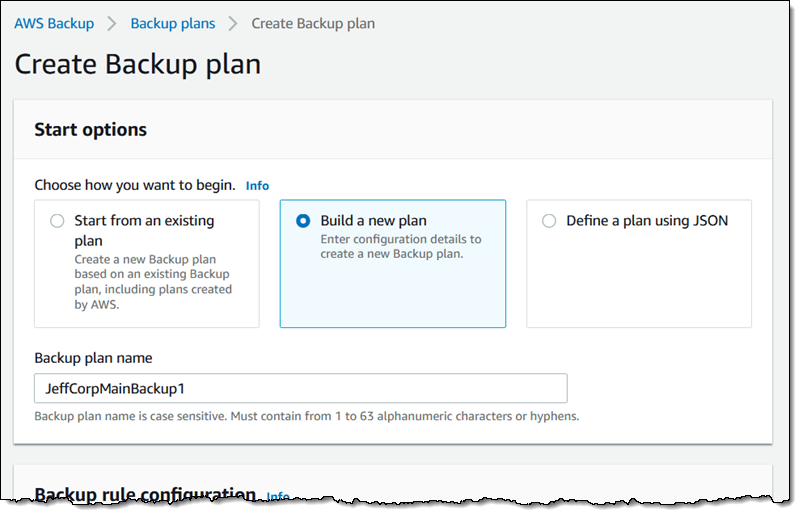
Now I create the first rule for my backup plan. I call it MainBackup, indicate that I want it to run daily, define the lifecycle (transition to cold storage after 1 month, expire after 6 months), and select the Default vault:
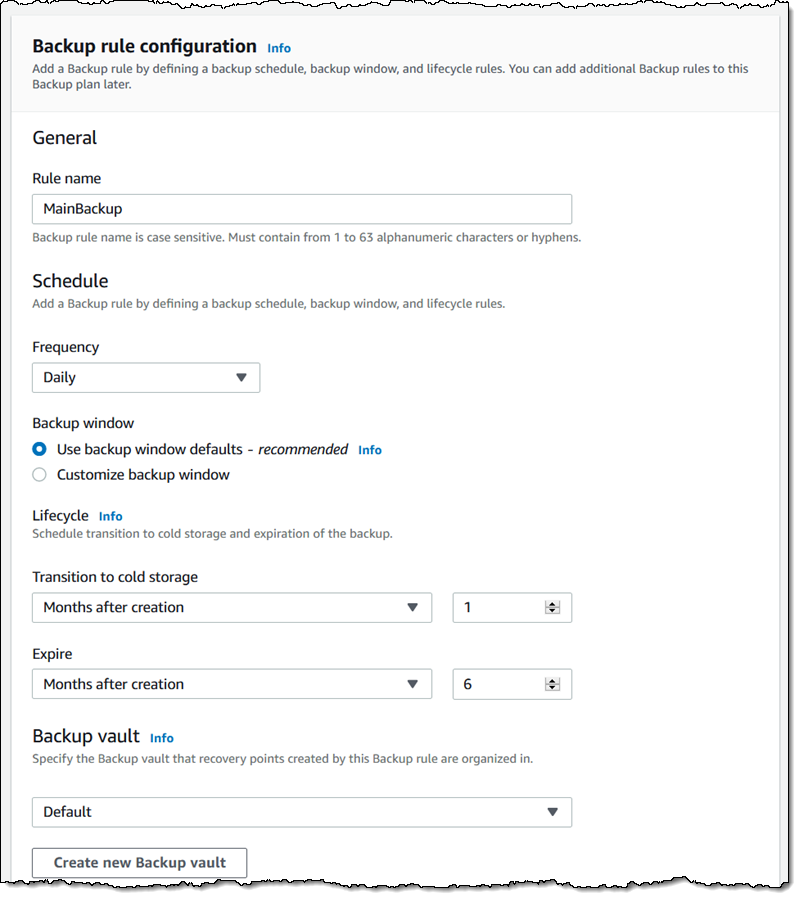
I can tag the recovery points that are created as a result of this rule, and I can also tag the backup plan itself:
I’m all set, so I click Create plan to move forward:
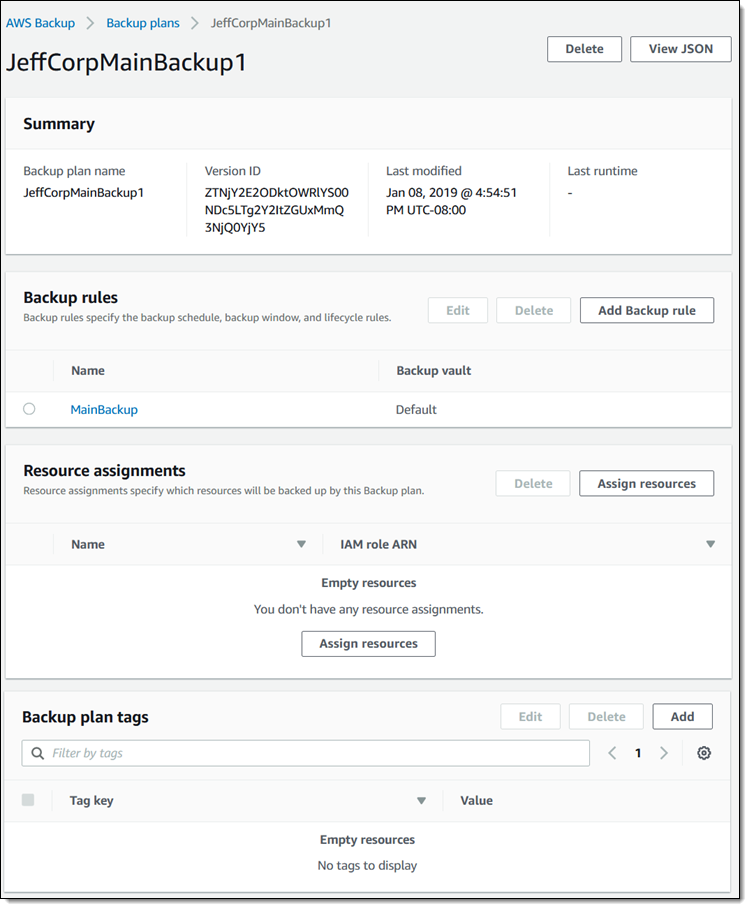
At this point my plan exists and is ready to run, but it has just one rule and does not have any resource assignments (so there’s nothing to back up):
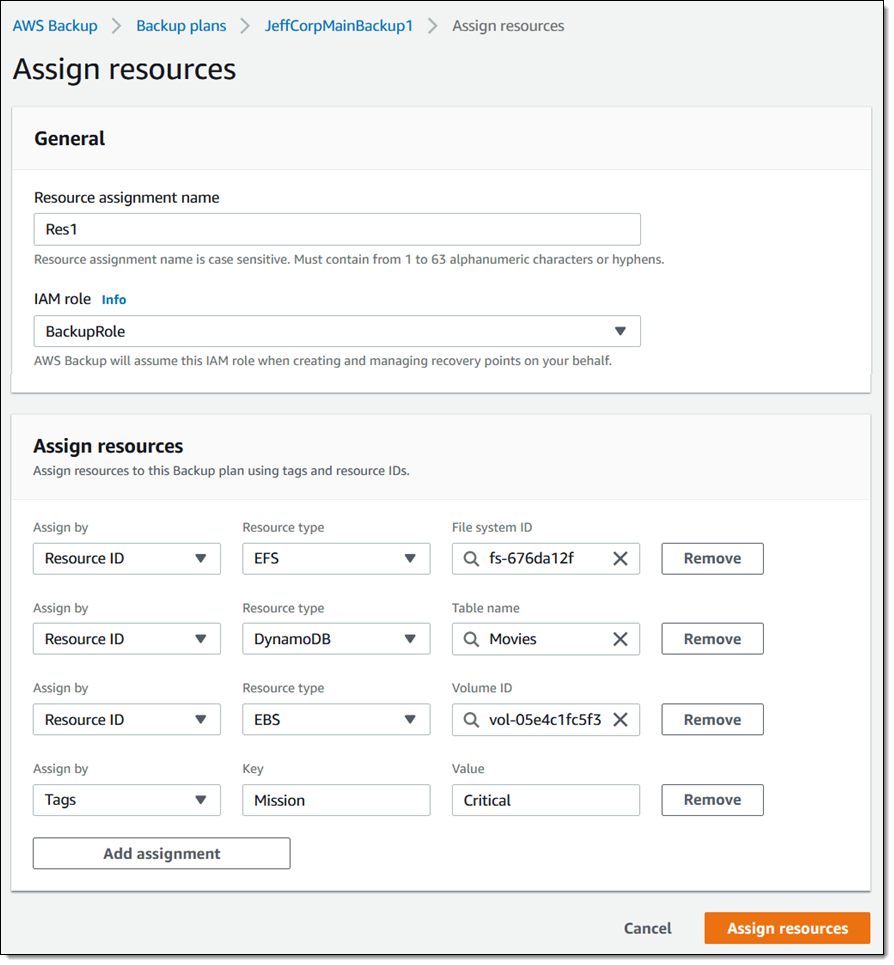
Now I need to indicate which of my resources are subject to this backup plan I click Assign resources, and then create one or more resource assignments. Each assignment is named and references an IAM role that is used to create the recovery point. Resources can be denoted by tag or by resource ID, and I can use both in the same assignment. I enter all of the values and click Assign resources to wrap up:
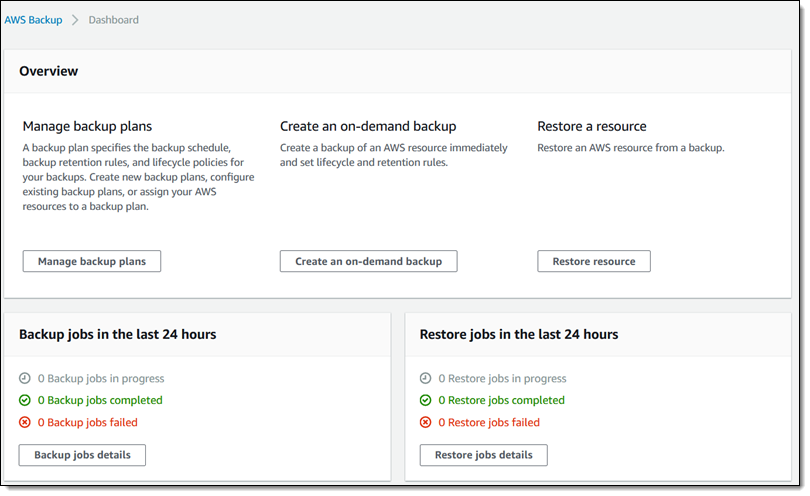
The next step is to wait for the first backup job to run (I cheated by editing my backup window in order to get this post done as quickly as possible). I can peek at the Backup Dashboard to see the overall status:
Backups On Demand
I also have the ability to create a recovery point on demand for any of my resources. I choose the desired resource and designate a vault, then click Create an on-demand backup:
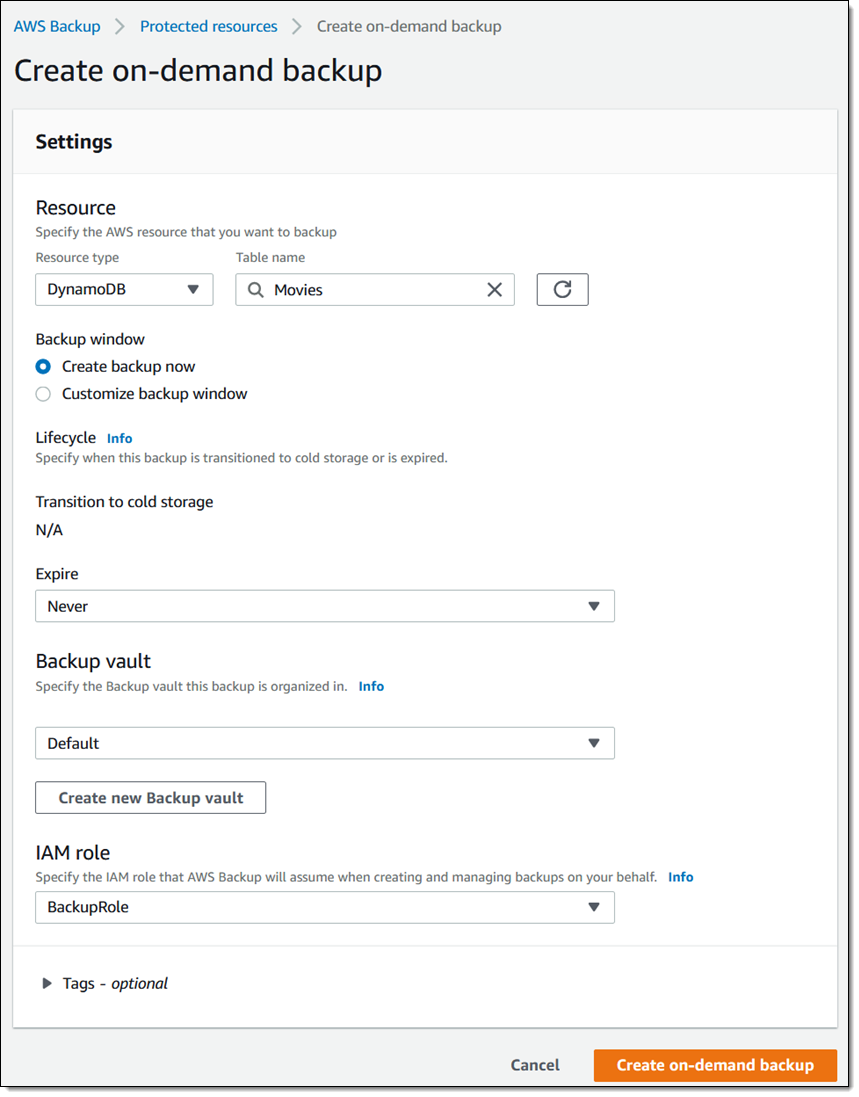
I indicated that I wanted to create the backup right away, so a job is created:
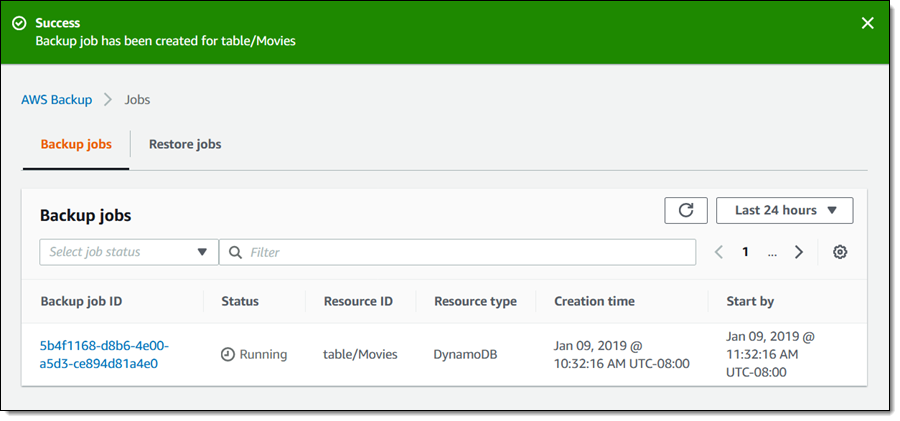
The job runs to completion within minutes:
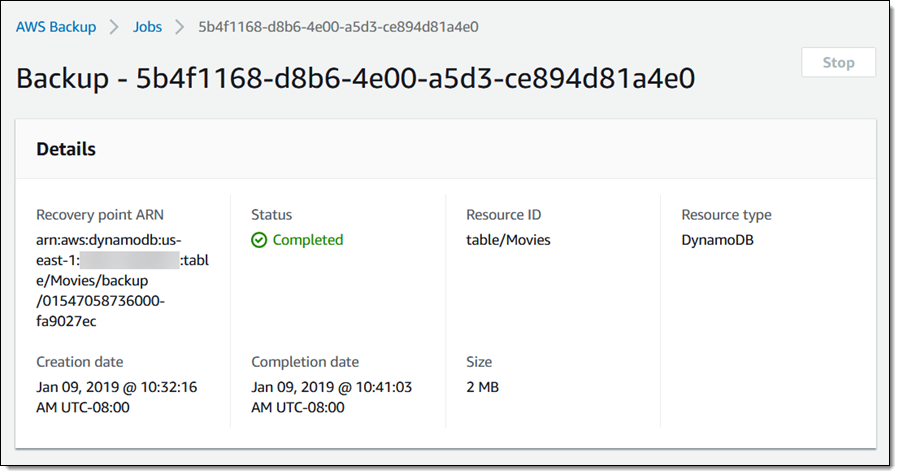
Inside a Vault
I can also view my collection of vaults, each of which contains multiple recovery points:
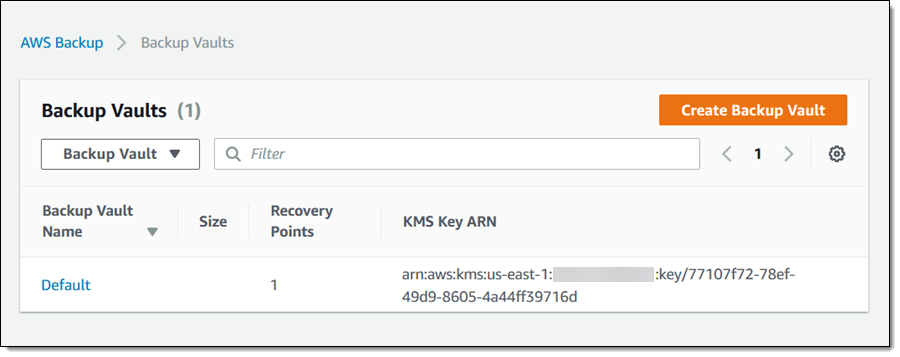
I can examine see the list of recovery points in a vault:
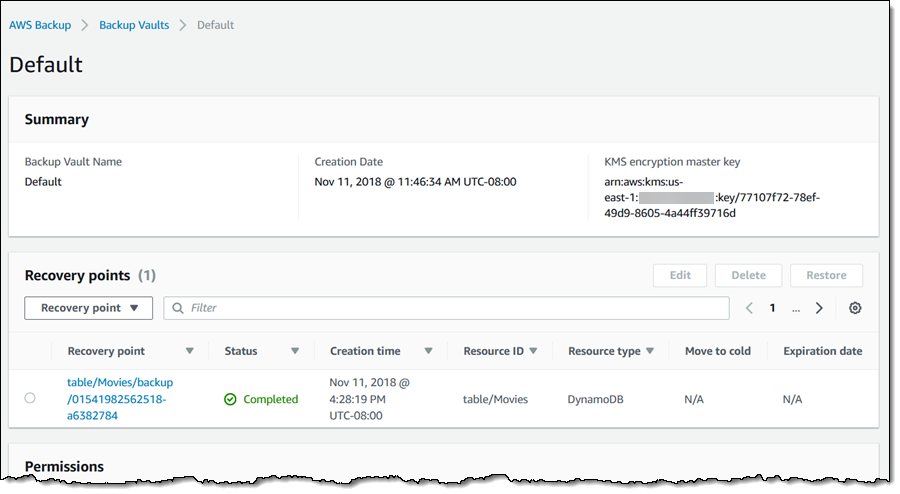
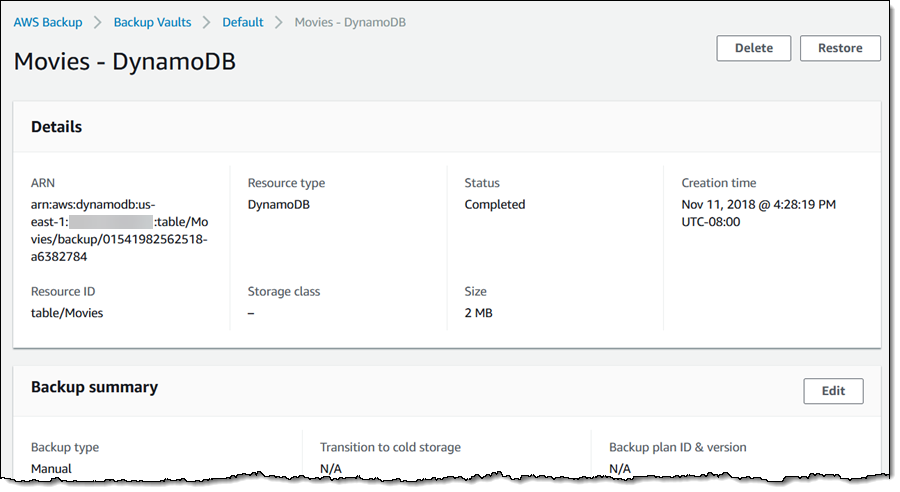
I can inspect a recovery point, and then click Restore to restore my table (in this case):
I’ve shown you the highlights, and you can discover the rest for yourself!
Things to Know
Here are a couple of things to keep in mind when you are evaluating AWS Backup:
Services – We are launching with support for EBS volumes, RDS databases, DynamoDB tables, EFS file systems, and Storage Gateway volumes. We’ll add support for additional services over time, and welcome your suggestions. Backup uses the existing snapshot operations for all services except EFS file systems.
Programmatic Access – You can access all of the functions that I showed you above using the AWS Command Line Interface (CLI) and the AWS Backup APIs. The APIs are powerful integration points for your existing backup tools and scripts.
Regions – Backups work within the scope of a particular AWS Region, with plans in the works to enable several different types of cross-region functionality in 2019.
Pricing – You pay the normal AWS charges for backups that are created using the built-in AWS snapshot facilities. For Amazon EFS, there’s a low, per-GB charge for warm storage and an even lower charge for cold storage.
Available Now
AWS Backup is available now and you can start using it today!
— Jeff;
PS – There’s a great AWS Backup discussion taking place on Reddit.
[ad_2]
Source link
Recent Comments